 In our series of interviews looking at The Art Of Synthesizer Design, we’ve previously featured Tom Oberheim, a pioneer who helped define expectations for analog synthesis; and Axel Hartmann, who has shaped the industrial design of synthesizers for the last three decades.
In our series of interviews looking at The Art Of Synthesizer Design, we’ve previously featured Tom Oberheim, a pioneer who helped define expectations for analog synthesis; and Axel Hartmann, who has shaped the industrial design of synthesizers for the last three decades.
Looking into the future, new types of synthesis can require entirely new approaches to interacting with sound. An example of this is Google’s NSynth project.
NSynth is a Neural Audio Synthesizer. It uses deep neural networks to generate sounds at the level of individual samples. Neural networks are a type of computer system, modeled on the human brain, designed to let computers ‘learn’ from observed data.
Learning directly from data, NSynth is designed to offer musicians intuitive control over timbre and dynamics, with the ability to explore new sounds that would be difficult or impossible to produce with a hand-tuned synthesizer.
To find out more about NSynth and what it means for both synth design and synthesis, we talked to Jesse Engel, above right, a developer that works in the TensorFlow, Magenta group at Google and part of the team behind NSynth.
This interview is one in a series, produced in collaboration with Darwin Grosse of the Art + Music + Technology podcast, focusing on The Art Of Synthesizer Design.
In this interview, Darwin talks with Jesse Engel about using artificial intelligence and Neural Audio Synthesis to create a new approach to creating and interacting with sound. You can listen to the audio version of the interview below or on the A+M+T site:
Darwin Grosse: Jesse, as you probably know, I recently had an opportunity to have a short discussion with Google researcher Douglas Eck about what you guys were doing with Magenta. But at the time, I imagined it to be more about decoding and generating musical data, as in notes. I hadn’t really thought of it as being something that would attack the concept of synthesis.
For all for those people who might not be familiar with the NSynth project, can you tell us what it is, and why synthesis seemed like a good target for some machine learning?
Jesse Engel: Sure. The project I have been working on is neural synthesis. We just call it NSynth for short. It is sort of an approach to synthesizing sound.
With previous techniques, if you have AM synthesis or FM synthesis, you would design individual components – like oscillators and filters – and then you would hook them up in various ways to try to create sounds that you have in your head, or maybe just explore new types of sounds.
What’s different about the approaches that we have been working on is that we use machine learning to help discover what these core elements of synthesis should be, and how to wire them up such as to make sounds. Rather than just exploring by tweaking a bunch of parameters with our hands, we have way too many parameters to do that with. We have like 300 million parameters.
So instead, we get a bunch of data, in this case we are using just individual sounds of instruments, and we have an algorithm that we train these 300 million parameters such that they automatically adjust themselves….to be able to make the sound.
That’s where the machine learning comes in. There has been some work in the past, where people had done some sort of automatic parameter tuning for synthesizers and these types of things, but we’re talking about orders and orders of magnitude more complex here. Because, what we have is the system is not just saying add this oscillator and this oscillator, but it’s really saying combine all these equations together and predict each individual audio sample.
If I were to present it with different data, like speech, it would learn good representations for producing speech. In fact, it’s been shown to do that.
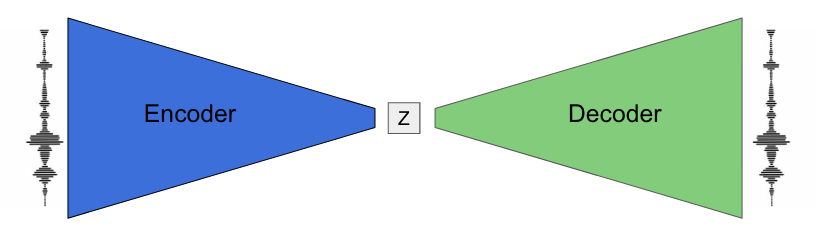
In this case, what makes it synthesis is the idea of focusing both the algorithms and the data set in such a way that we have the goal of making a playable instrument, something that is a playable surface that we can use to make music.
Darwin Grosse: Just he concept of 300 million parameters is kind of a scary thing.
Now, obviously, someone didn’t sit down with a piece of graph paper and say, “Parameter one is gonna be this…..”
Jesse Engel: Yeah. Unlike other attempts….there’s not me saying, “Okay, the sound is made up of frequencies, and transients, and of these types of things.”
It’s most similar to an infinite impulse response filter. That type of thing. But sort of like a reverb, where it’s a feedback system. It takes the output and it feeds it back into itself.
But it runs through this complicated mathematical function to say what should be the next sample, given the previous samples that came before. What’s interesting is the way that we train this is it just has to predict, that I think the next sample should be .5, and then between one and negative one, or something like that.
Then we have the real data, and the real data says, “It was actually .8”. It says, “Oh, I know that I was wrong. I should have guessed .8 instead of .5.”
What’s nice is that the breakthroughs in machine learning these days, called deep learning, is really just that you can attribute, each parameter we can propagate that information back to each parameter. Say, how much should this one have been higher and this one have been lower, such as to make it .8 instead of .5.
Darwin Grosse: Right.
 Jesse Engel: Well that’s the automatic tuning, that’s the machine learning. It’s basically high school level calculus, but just done at an incredibly large scale. Basically, you’re saying which direction should you move? That’s like calculus.
Jesse Engel: Well that’s the automatic tuning, that’s the machine learning. It’s basically high school level calculus, but just done at an incredibly large scale. Basically, you’re saying which direction should you move? That’s like calculus.
We have this nice open source software called TensorFlow that allows all of that to happen automatically. You just define the functional relationship. You define, “I think that this next sample should be related to all the previous samples via these functions.” Then it learns the parameters of those functions.
Darwin Grosse: Interesting. Yes. Sort of imagining it as a really really complex IIR (Infinite Impulse Response), or even sort of like a bizarro convolution. It’s an interesting way to imagine it.
Jesse Engel: It’s actually 30 layers of convolution. You do a convolution, and then you do another convolution, and another convolution. But then in addition, convolution’s a linear operation. Right?
Darwin Grosse: Right.
Jesse Engel: We have a bunch of non-linearities as well. It makes it a much more rich type of system.
Darwin Grosse: Very interesting. On the NSynth web page, you provide some information about how it’s done, and you also provide some audio samples. It’s really interesting to listen to them, because – while it’s not a completely emulative thing – the synthesized version of the sound would often key me into details of the original that I might not have even caught.
Especially I noticed on a couple of sounds that there was release noise that would happen with the sound that I wasn’t even really aware of, because I’m so used to recordings where it has some kind of schmutz at the end, and you just ignore it. Right?
Jesse Engel: Right.
Darwin Grosse: But then I’d listen to nSynth’s synthesis of it, and it would be very particular about emulating that release noise in a way that made me aware that there’s a detail that I just glossed over in my mind. It was really interesting to hear that.
Jesse Engel: Well, what’s interesting is that, since it’s just predicting the next sample, it’s actually predicting the shapes of these waves. It’s actually doing some sort of wave forming, wave shaping stuff.
Darwin Grosse: Right.
Jesse Engel: What’s interesting is that…if it makes an error in the prediction of the actual shape of the wave, that comes out in the harmonic content.
It’s harmonic distortion. Not inharmonic distortion. There are a lot of interesting artifacts. When it fails, it fails in a way that makes sense to us, because it’s modeling instruments that actually have harmonic relations due to the physics of the instruments.
It sounds, really rich in the distortion, similar to running through a tube amplifier, or just any of your favorite analog gear and stuff. But it’s an entirely digital system, because it’s modeling a analog process.
It’s a lot more like a physical process in that way.
Darwin Grosse: One of the other things that I really thought was, in a way kind of hilarious, in your examples was where you play a scale, and then recreate it, using a detection system that hadn’t really been tuned for pitch stepping.
Jesse Engel: Yep.
Darwin Grosse: It was interesting to hear how it coped with that just by smearing the edges, but still paying attention to those wave shapes and the timbral shape changes, and the harmonic changes. It was funny but really surprising at the same time.
How often when you’re working on this stuff are you just totally surprised by what comes out the other end?
Jesse Engel: Definitely more often than not!
I wish someday that I would just publish all the crazy sounds. These are models that “work”. But there are lots of beautiful mistakes that happen when the models don’t work as well.
In that case, what you were talking about, that was a nice built in feature of the model. Like I said, there are 300 million parameters. Right? But we don’t want to be able to control all of those. We want to expose a control surface that’s actually more amenable to human manipulation.
What we do is we force it to go through a bottleneck, where it learns just a couple, 16 parameters, and how those 16 parameters vary across time. But since it learns how they vary across time, you can – even though it was only trained on single notes – you can stick in things with multiple notes.

In the follow up blog post, Making a Neural Synthesizer Instrument, there are a whole bunch of examples of manipulating these 16 numbers – including if you were to play stuff that’s not trained on multiple notes. It tries to capture those multiple notes. so it uses upper harmonic content to try to somehow induce polyphony.
It’s only ever seen one harmonic series at a time, so it can end up just sounding really distorted – kind of like Jimi Hendrix just putting his guitar right up to the amplifier – in a really awesome way.
There’s lots of cool, pleasant surprises about. In machine learning we call this bias.
If you’re designing a synthesizer, you’re biased by the functions that you’re designing the synthesizer with. An FM synthesizer sounds like an FM synthesizer, because of the bias. It can’t explore all sounds, it just explores the sounds that are most natural to it.
The bias in the machine learning system is both the model that you use, and also the data that you trained it on. It has this bias, based on the data that its heard. In this case, individual instrument sounds.
So, if I show it examples of me talking into it, and then it tries to reproduce my voice, it does so as if it had only heard instruments.
It sounds kind of like a vocoder, but it’s distinctly different ’cause it’s a feedback system. It’s not a feedforward, like a filter system. It’s like this infinite feedback system. So it doesn’t matter if I’m using it to morph between different instruments, including a violin or a piano or whatever, it sort of always sounds a little bit like itself, due to the bias of how it’s learned the system.
That’s why I called it neural audio synthesis – it’s just the idea that this was one algorithm and one data set that we could do. But I can imagine many many other ways of using machine learning at this scale to produce sounds. Hopefully we’ll see a lot more of that, and we can call a whole family of algorithms belonging to this, similarly to our FM synthesis as a whole family of implementations and that kind of stuff.
Darwin Grosse: The things you talk about are steeped in, you claim that it’s high school calculus. It still is the kind of calculus that makes my ass twitch. Right?
But it’s driven by math, it’s driven by the science of machine learning and data manipulation. There is plenty of computer science that gets involved. But also you have to have an awareness of both audio, DSP type functionality, as well as just the general tenets of audio and what makes audio good and bad.
I am curious about how a person like you pours all of this stuff into one brain. Right? Where do you come from? What moon of mars did you come from that you have skills in of these different areas?

Jesse Engel: Probably Deimos, I think. My background is actually in physics. I did my undergrad in physics, in astrophysics.
I studied that Martian atmosphere for my undergrad. Then for my PhD I wanted to work in renewable energy, so I worked on nanotechnology in solar panels. I have a PhD on quantum dot solar panels.
In the time, during that, I was really interested in complex systems. I had started to hang out with the neuroscience guys, and I did a postdoc combining computation and neuroscience ideas to do next generation storage.
Then I got hired away from that to help startup a speech recognition lab with Baidu, in the Silicon Valley.
Darwin Grosse: Yeah.
Jesse Engel: I did that for a little while, and we had some great results there. Then I heard that Doug (Eck) was starting up this project at Google, doing creativity in music.
All of the way along, I’m a jazz guitarist, and an improv rock guitarist for 15 years. I have always been, in my free time, playing with different looping, and other types of technologies.
This just seemed like a great opportunity to make it all happen. Interestingly enough, I started coding with Ableton, and then Max/MSP was my introduction to coding. As a guitarist, it makes sense – you are just dragging wires between things and stuff.
This was during my PhD. Then I wanted to go deeper, so I wanted to open up the boxes inside Max.
I did a little Java, a little C++ to get in there. Then I realized everything had a Python API. In my post-doc, I just did Python for everything. Then all of a sudden the work at Baidu was all C++, and then I knew how to do all this coding stuff.
Darwin Grosse: Wow.
Jesse Engel: But the DSP principles and stuff – Max tutorials. Also, David Wessel at UC Berkeley, I used to hang out a bunch with, because I was doing the avant-garde jazz scene over there.
So great inspiration for me in terms of trying to connect these concepts, and connect computation and music and all of these types of things.
Darwin Grosse: David was a great inspiration for an awful lot of the people that I have talked to over the years. He was an amazing man.
Jesse Engel: Yeah. I went to him for advice when I was finishing my PhD.
I wanted to do something different, but I didn’t quite know how to get there. He was really helpful for me for just helping to bridge those gaps.
Darwin Grosse: When I was teaching, I would talk to people and say, you know, the job that you end up getting when you get out of school probably doesn’t exist right now.
That’s a common trope for university professors. But you ended up with a job that didn’t exist like 15 minutes ago. Right?
Jesse Engel: Yeah.
Darwin Grosse: You doing what you’re doing – is part of that just the nature of being in the Valley, and being tapped into what people are doing? Or were you actively checking our specific area? Did you feel like machine learning had some legs in this area?
Jesse Engel: I’m really grateful for my job. I keep on saying, I can’t believe they pay me to do this. ‘Cause really, it’s not just working on creative machine learning, it’s having great support from the company, and having everything be open source. It’s really fantastic.
But I think I have always been looking …
I got a good piece of advice a long time ago – you can’t always make the opportunities happen for you, ’cause sometimes the opportunities don’t exist. But if you always keep yourself going, if you look at each next step, and you’re like, does this take me in the direction that I want to go? Are there things that I can learn here? I always could answer yes to that with each step in my process, even though it wasn’t exactly where I wanted to be. If you keep doing that, you’ll be aware that when the opportunity arises that is the opportunity that you’re looking for. You’ll know that that was what you were looking for and you can just jump on it.
That’s what happened with me with this job. It was just clear ’cause I had been looking for a long time, but just sort of aware of it when it became time, I was like, okay, this is what I gotta do. I actually got the job through meeting, I went to a machine learning summer school, where I met Anna Huang, who was going to be an intern with the group. She was an intern with the Magenta group. I was just touching back, and we naturally gravitated to each other, ’cause she did this chord to vector embedding type of thing. It’s like, oh, music and machine learning. You attract to those people that are common to you.
Darwin Grosse: Right.
Jesse Engel: I just emailed her, I was like, “Hey, I’m just looking around. What’s happening?” She is like, “Oh, by the way, Doug is starting this cool group that you should check out.”
You self-gravitate to people that are of a like mind of you. Then the opportunities get created because you want to hang out with people that do cool stuff and stuff that you like.
Darwin Grosse: Did you have any failed attempts? Did you get into things that just didn’t work out or didn’t feel right for you? Or have you lucked into the good side of everything.
Jesse Engel: No…I wouldn’t say failed attempts. But working on my PhD, I was handling a lot of toxic chemicals. There was a lot of mixing of toxic chemicals together. We would sort of paint on solar cells.
But in order to do that, the only way we knew it at the time was with this toxic stuff. Then you learn the principles, and maybe looked at a non-toxic.
There were some people that this just came naturally to, and they loved it. Sort of like some people like climbing mountains. This was clear that this is what these people should be doing. They love this. Frankly, I didn’t love it. I would come home and take a shower. It was not the right thing for me to be doing long term.
It was still very intellectually engaging, I learned the stuff, and I followed through. Still following through and completing it to the point where it was something for me to stand on, such that when I went to my post-doc I could say, look, I know how to do all this nano-technology stuff, and I don’t know how to do this neuroscience stuff. I can leverage that to give myself a learning opportunity.
But it wasn’t an easy time. I was taking time to find things that are more resonant with, basically what are the things that you enjoy doing when they’re not working? You know?
Darwin Grosse: I see. Right.
Jesse Engel: This thing’s not working, it’s just making weird sounds, and I’m going like, “Oh, hey that awesome. This is fun.” When the chemistry is not working, you’re scrubbing out things with other toxic solvents.
For some people, it’s cool because you’re doing new things, and new science. But it wasn’t what has that natural resonance for me.
Darwin Grosse: Sure. So you suggest that you came to coding a little bit late. But when you did, you came at it with a vengeance. It sounds like you learned all the languages. Whether it was Max, or C++, or Python or whatever, you had a lot of experience in a lot of different coding languages.
But when you got into machine learning, machine learning is also the world of Python. Python generally isn’t the world where music technology lives. It strikes me that you had some sort of a job, just to get the machine learning world to talk with the audio and DSP world. Right?
Jesse Engel: This is actually one of the things that we encountered a lot with this Magenta project…which is that TensorFlow has a lot of APIs.
At the bottom, it’s actually C++. But it has a lot of APIs to other languages.
But Python has been emerging as the lingua franca of machine learning. There is also Lua for Torch, but that’s sort of died down in favor of PyTorch, which is in Python as well. For better or for worse.
I happen to think it’s great to at least have one language which a lot of different things can communicate with. But unfortunately a lot of different music software, it’s JavaScript or other types of things.
What’s interesting is it’s sort of the same situation that hardware manufacturers have had to deal with for ages in software. There are music protocols for communicating, but they’re MIDI, and Open Sound Control and these things. We basically separate the world in that way, that as long as we have all the components talking to each other with MIDI, it doesn’t matter if our TensorFlow unit is running in Python, and it’s sending MIDI to Ableton Live, or an actual piece of hardware.
That said, we’d love to get more stuff. Browsers seem to be really an interesting space, and also with Processing, it has the JavaScript version as well. We’d like to be able to get more of our models actually running in the browser, running in JavaScript, for more interactive experiences.
Darwin Grosse: That makes sense. When I was out there for a visit, when you guys did some of the stuff with the note and the phrase learning, you were piping that into Ableton Live generally, as the way that you gave it voice. Right?

Jesse Engel: Yeah. This is really my bias, just coming from Max for Live and Ableton, and those sort of things. We had this browser version, and I was like, “Hey, we could make this a lot more musical and a lot more useful to people if we integrate it with Max.”
I think we have right now, on the open source repo, we have a system that communicates back and forth between the Python and Ableton, but then it also uses a Max patch with Mira, so that you can use an iPad to interact with it. It was just to make it really a smooth demonstration for this one machine learning conference – this neural information processing systems. It was tailored to that.
But yeah, it’s trying to find ways of making these things more accessible to a broader range of musicians that don’t know how to use command line, this type of thing.
For the synthesizer, the current implementations of these things are very computationally expensive. It takes minutes just to synthesize a couple seconds of audio.
How do you get around this barrier? One way I did it was, Google has a lot of computing power. I used a lot of Google computer power to synthesize a bunch of audio ahead of time, and then I wrote a Max for Live device which you can find on the blog, that actually just works as a multisampler. I defined this space of instruments, like a grid of instruments, and then you can drag around in this grid. It just plays the sample from what’s the closest interpolation within this grid of instruments. I pre-sampled the whole grid to create a smooth perception.
To make it even a little bit smoother, I’d actually take the four nearest sounds, and then I mix the four of those Audio Space.
One of the cool things about the neural synthesizer is it learns this code, these 16 numbers over time. You could have two different codes for two different instruments. You know? What’s nice about it is it’s a semantically meaningful code. If I just mix the two, if I just take the mean of the two and add the two together, if I do that with the numbers, the waveform, if I do that with two sounds, it just sounds like two independent sounds. I could have a cat and a flute and they sound like just a cat and a flute in a room.
Darwin Grosse: Right.
Jesse Engel: But if measure the numbers in the lead-in space, and resynthesize the audio, then it comes out with something that has the dynamics and the timbre of the two combined. It sort of sounds like a flute that meows or something like that.
I can synthesize all of these different mixings of these different instruments, and we can play it on a laptop.

Darwin Grosse: Yeah, the cat-flute though, I am not sure that that’s the winner. I’m not sure that’s what we’re shooting for.
Jesse Engel: Yeah. That’s the winner of the public audience. There are no cat-flutes in the Ableton instrument! It’s more orchestra, and organs, and synthesizers, and these types of things
But this is just really the first step in this direction. There is the whole wild west of ways to expand this work, and that’s where I am going right now.
Darwin Grosse: Well, one of the things that’s interesting to me is, in a way you are experiencing computer music development in an extremely classical way, where this concept of requiring a long period of time to generate a short amount of data.
I just actually interviewed composer Chris Dobrian a couple of weeks ago. He talks about how one of the real difficulties in the earlier days of computer music was this concept of, you hoped. You hoped that this big algorithmic thing that you put together would produce something useful. If it didn’t, it was sort of like, well I’ll never get that amount of time of my life back.
Jesse Engel: Right.
Darwin Grosse: Now in their case, a lot of times they were talking about hours rather than minutes, but it still must be a little bit frustrating. We’re so used to now to having extreme real time stuff, to the point where it’s like, if something has 50 milliseconds of latency we’re just throwing up our arms and saying, that’s unusable.
Jesse Engel: Right.
Darwin Grosse: How do you, as a musician, as someone who is used to working with all of these realtime tools, how do you cope with some of this stuff that is so incredibly computationally intense?
Jesse Engel: Yeah. I’m a jazz musician. I’m really all about the realtime interaction. And we’re trying to push the algorithms in those directions.
But right now, they’re not, at least for generating the sound one sample at a time. It’s kind of an interesting thing. It’s the same creative loop that you would do normally. Where you real time make a sound, and you’re like, “Oh, maybe I should shift it this way to make the sound different.”
It’s that same creative loop, but just the time in between you hearing the sound and making a new sound is much larger, especially depending on how many sounds you’re making.
So, you have to think more in parallel, where you’re like, rather than let me try this one combination, you’re like let me try these 1,500 combinations. Then, when you’re going around through the presynthesized 1,500 combinations, it feels more realtime, because it is realtime playing it back to you.
Darwin Grosse: Right.
Jesse Engel: You have to define the space ahead of time.
Given that you listened to all of that stuff, and you do that for a while. Then you define a new space to explore. It’s sort of a similar. With composition,
I have made a song using our melody generation thing too. It was a similar idea, where rather than just play one melody and have it hear what it says, I had it generate a thousand melodies. And I would just go through and listen, listen, listen, be like, it’s sort of more curation. Right?
I’d be like, “Oh, this is a good one. I hadn’t thought of this.”
Then I would build off of that, and feed it back in, and have it generate a new 1,000 melodies off of that. It’s sort of a different process of thinking about new things.
Darwin Grosse: You said something a minute ago that caught me, which was this idea that there is time to think through, or imagine what you’re gonna do, instead of just literally, physically doing something.
In my mind, when I cast it back to the greats of early computer music work, I imagine these people setting up a process and then stroking their chin for two hours, contemplating what their next move was gonna be once they would hear this result.
I was like, well that contemplation over your synthesis methodology will probably never happen again. Except now you are having it happen again.
So, it’s interesting to hear what is your chin stroking looking like? In this case it looks like obsessively banging on a 1,000 play buttons, to listen to the different things that it generated, which is interesting.
It strikes me as being like this thing, I think it was, maybe it was Eno that talked about how you generate a lot of material, so that your editing function has the opportunity to be very picky. Right?
Jesse Engel: Yes. Very much so.
Darwin Grosse: And that that opens really interesting doors when you can do that.

Jesse Engel: You can’t just say, “Create me 1,000 things that are all wild and crazy.”
You can, but there is a certain way that we train them, that it’s trying to identify the core elements of these sounds. Sometimes the core elements of stuff is the more bland stuff, that is like, okay, that’s fine, it sounds like a trumpet. But I was really more interested in that thing that was like 10% trumpet and 20% drum, or whatever!
It’s nice to generate a lot of (options) in bulk, and then be very picky with what you pull back out of it. It allows you to extract the most interesting stuff out of the algorithm itself.
Darwin Grosse: You mentioned before about how there are a lot of things that people haven’t heard, because they were what probably are considered failures.
I would think that this has to be sort of a conundrum for you, as both a creative person and as a science person.
Because when you go to a machine learning conference, what people really want to hear is, they want to hear you come as close to generating a real trumpet sound as is computationally possible. The closer you are to a trumpet, the more likely it is that people deem you a success. Right?
Jesse Engel: Right.
Darwin Grosse: Where in creative terms, the closer you come to the cat-flute, the more likely you are to be able to be treated as the brilliant creative guy. Right?
Jesse Engel: Well, I’ve really noticed, when I show this off, there are two responses.
One, is just sort of along that line of, okay, well can you make it sound more natural? Can you make a better violin than the current violins? I think that totally misses the point.
It’s sort of like the original 808. It was supposed to be accurate. Right? But the beauty of it is that it’s not.
The beauty of it is that our real metric is not just the sounds in terms of the accuracy, but the way that it engages people as musicians, and in the way that it engages your creative processes, in order to create new experiences, and take you to places that you weren’t expecting.
Darwin Grosse: Now, in your experience, and erring on the side of creativity, ’cause I frankly think that the current violins are violin enough. I would like something different.
You get the chance of feeding this system all kinds of models, and all kinds of data. What are the things that, first of all in the general case, that you find most interesting. And what are the things that actually take these algorithms kind of to their limits?
Jesse Engel: Right now, what neural networks do, and these machine learning algorithms, is they really, if you can imagine, just imagine a space like a grid. You can imagine that there is, putting a bunch of instruments might be your data points. Moving between those instruments, where you have data, is something that neural networks do really good. They smooth out the rough edges, such that you can smoothly transition between your data points.
Then when you go outside those data points, it fails in really weird ways, but also not necessarily weird in a good way. It can be weird, like white noise. You want this balance of structure and chaos.
But it can just be chaotic out beyond the range of data.
What happens if you take a line and you just draw it off, far away from whatever you were training on? Does it maintain whatever kernel of it was doing? If I go between the flute and the bass, and then I go out beyond the bass on that line, you would get something that is to bass as bass is to flute. You know?
More bassy, relative to flute. It would be along that line.
These musical analogies, where you get these knobs that you can turn on your control surface that you can combine together in interesting and independent ways.
There is something beautiful about a way that a synthesizer specifies. You have these components, and you can really just tweak them and find all the combinatorial ways to add these things together to get something really interesting.
We don’t have systems right now that learn structure. They learn the rules at a level where you can then just mix and match your rules. It learns a holistic representation of a sound.
What we would like to do is be able to learn, not just holistic representation, but also somewhat reductionist representations. Because right now we use our own minds for the reductionist representation. But it would be cool to be able to learn these nuggets of actual concepts, that we can then mix and match in combinatorial ways, and have a much more creative process with, rather than just moving around holistically between already pre-existing sounds, and those types of things.
Darwin Grosse: That is naturally almost answers the next question I had, which was how do you take the concepts of what machine learning is good at, which is this interpolation, and give the driver, or the instrumentalist, more than just a single joystick of control to interpolate between a cat, a flute, a bass, and a dog.
That’s what you’re talking about – finding useful ways of reduction, but in ways where there is still a lot of variability in what the end result is.
Jesse Engel: If you are trying to design a circuit or a synthesizer, it’s hard to wire together the components in the right way, and figure all of these things out. Where should the components meet? It’s hard to do that in an automated fashion.
If I just say, give you a sound, and say, okay wire up a circuit that makes this sound. It sounds pretty audacious. Right?
But what’s interesting is that these networks are finding good compact representations of what sounds are. You can use those representations to then train a system that works in a different way, where it’s not smooth, it doesn’t know exactly how much to change, all the parameters to exactly match the sounds, it has to make harder decisions. Like, I’m gonna combine this circuit with this circuit, and I’m gonna do these things.
That’s where I see the next generation of this is.
You have machine learning models that understand the world in its complex, statistical manner, but aren’t good at distilling that down to concepts. Then you train a model to learn the concepts behind. You learn the abstract model of a ball rolling down a hill, or a string vibrating through a filter, and these types of things. Then you can use neural networks to go from the simplified abstract way of thinking of things to the more beautiful complex statistical things that we’re used to hearing.
The natural sounds have so much complexity to them, and neural networks are good at modeling that complexity. But that there also is a simple way of looking at the complexity of things. Like, oh, it’s just physical model. It’s just a string vibrating. But that doesn’t capture all the complexities.
There is some beautiful balance between the two of these that I can see happen in the future. You have a sort of pairing of models that understand the complexity of the world, and models that understand the simplicity of the world.
Darwin Grosse: Just even imagining a system that’s able to say, “We can take 60% of this and just extract it into the string thing, because that’s really string. We can take these things, and it’s a resonant body, and kind of pull massive sections apart.”
That’s a hell of an analysis process.
Jesse Engel: This is why it’s all speculative research. But this is all why it’s great that we’re in a world-class machine learning environment. The Google Brain team is the official large team that we’re a part of.
Darwin Grosse: Right.
Jesse Engel: These are great resources, in terms of people that don’t think about sound. They think about statistics, Bayesian reasoning, and all of these things.
But they are resources to me. I can go talk to, and help them think about, “Well, how would I apply this to this context? ”
It’s a cool situation to be in.
Darwin Grosse: Now in that situation, do you ever find yourself having to get down to the level of teaching a statistician musical concepts? Or do you find a way to avoid having to go down that road?
Jesse Engel: A lot of the representations that we work with, they learn the biases. Right?
They’re pretty agnostic to some of these things. There are definitely points where, at some point I’ve gotta break it down to the phase and variance of the spectrogram, or something like that.
But it’s usually not a stumbling block in anything, which is the great egalitarian part of this machine learning stuff, is that there is definitely a place for expert knowledge. But it’s more put into curating the data sets, and these types of things.
Expert knowledge is still valuable, but it’s more of a bonus.
Darwin Grosse: Where a lot times I ask people to cast into the far future, with you I’m gonna do the opposite – because I think the far future of machine learning is too bizarro anyway!
In terms of bringing some very basic levels of machine learning to musical and recording results – what do you think is likely to happen over the next couple of years?
Jesse Engel: I think one thing that’s definitely going to happen is the commercialization of generated music. I think there are a lot of companies, like Jukedeck and others, that are working on making music that’s palatable for people to listen to, behind a YouTube video or something like that.
That is something that is not doable right now, but is within reach within a year or two. I think that will have large impacts, but I don’t think that’s the interesting question. I don’t think that’s sort of we want to be going with this.
Where I do think that things are headed is definitely mapping, like having high-dimensional, realtime control, over naturalistic sounds.
Imagine all different ways of mapping new types of controllers into, not just controlling the different oscillators in a synthesizer, but really taking a system that’s more advanced than the one I’ve made so far. Really exploring such a large range of sounds, not just individual notes, but music……
I think we’ll be looking at a lot more physical, interactive systems. I think that’s within the two year horizon, for sure.
Darwin Grosse: Jesse, I want to thank you so much for the time that you’ve taken out of your schedule.
Jesse Engel: Thank you so much. It was good talking to you.
NSynth Ableton Live Instrument:
You can download the NSynth Ableton Live Instrument via Magenta Tensorflow (.zip file)
Additional Resources:
- Jesse Engel on Github
- Magenta
- Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders (pdf)
 About Darwin Grosse:
About Darwin Grosse:
Darwin Grosse is the host of the Art + Music + Technology podcast, a series of interviews with artists, musicians and developers working the world of electronic music.
Darwin is the Director of Education and Customer Services at Cycling ’74 and was involved in the development of Max and Max For Live. He also developed the ArdCore Arduino-based synth module as his Masters Project in 2011, helping to pioneer open source/open hardware development in modular synthesis.
Darwin also has an active music career as a performer, producer/engineer and installation artist.
Additional images: Google, Alison Groves

“Open the lowpass filter HAL”
“I’m sorry Dave, I’m afraid I can’t do that”
Joking aside this technique seems very interesting and I’m gonna try this instrument out right as soon as I get onto my ‘puter.
But can it learn Trap music?
Brilliant stuff, obviously.
But it also makes me think of the infinite monkeys idea. (The theory that, if you give an infinite number of monkeys a typewriter and all the time in the world, eventually they’ll type the works of Shakespeare.)
The way I interpret that idea is that the monkeys won’t realize that they typed the works of Shakespeare and don’t even understand English. So somebody would have to wade through an infinite stream of random junk to find the Sonnets.
This sort of seems like that’s where this neural synthesis is – somebody’s got to wade through all the randomness to find nuggets that are actually interesting. Is that making computers ‘intelligent’ or is it training us to wade through a random string of junk to look for something interesting?
Even though they run through the description of the process, i think i get where you’re coming from.
AFAIK deep learning involves a set of rules in order to specify a direction such as the one you’re asking for. Even though it might be a extremely complex process, i’m not sure it’s very random at all, but rather a really thorough process of running through the combinations of parameters systematically. What do you think?
Big tech companies are now becoming more musically innovative than big instrument manufacturers. Would hope for more creative syngergies between these industries.
They have a lot of things going for them that no music industry company has: the AI experience, deep pockets, entire server centers to leverage and no requirement to contribute to the company’s bottom line.
The big question is not whether they can do interesting research, but if they can turn it into an actual product – Google is notorious for doing stuff that never goes anywhere.
Jert’s Infinite monkey scenario…
“The way I interpret that idea is that the monkeys won’t realize that they typed the works of Shakespeare and don’t even understand English. So somebody would have to wade through an infinite stream of random junk to find the Sonnets.”
I think you have perfectly captured the end result of everyone on the planet having the ability to “make music” with their laptop, iPad and/or phone. All of the monkey’s may have typewriters, but in this scenario, only one monkey had any serious business with one.
Wading through an infinite series of junk almost perfectly describes a visit to SoundCloud or BandCamp.
Probably accurate but this monkey likes having fun – if only I could’ve been satisfied with just the one ‘typewriter’ though .
The most interesting direction for synthesis development is currently in the area of realtime expression. See the Continuum, Seaboard Grand, LinnStrument, etc.
Right now, though, only the Continuum has a synth engine that’s up to the controller’s capabilities.
Could AI be used to map expressive gestures on a controller to synth outcomes, iteratively?
In other words, could you have an virtual instrument that learns from your playing and your desired outcome to bring the two closer together? I.E., if I’m playing virtual trumpet, could it learn how I play vibrato and then turn that into ‘trumpet vibrato’?
All of the monkeys had fun with their typewriters. That is a given.
Hell, I’m one of them.